04 May 2025
In part 1, I detailed the challenges inherent in using Core Image to produce an NTSC video filter for Apple platforms, building up an alternative processing pipeline in Metal. In this post, I’ll discuss how to integrate this approach into a whole application, following MTLCommandBuffer through multiple processing steps, and integrating it with some common flows.
Command Buffers Redux
To recap, MTLCommandBuffers contain the serialized function calls and references to data structures needed to run code on the GPU. In order to implement our NTSC filter, we’ll append the multiple function calls we need to the single command buffer we’ll use to render the frame:
- Convert RGB data to YIQ
- Composite preemphasis
- Video noise
etc.
The actual implementation of this looks like:
guard let commandBuffer = commandQueue.makeCommandBuffer() else {
return nil
}
let textures: [MTLTexture] = ...
let pool = Pool(vals: textures)
do {
try Self.convertToYIQ(
try pool.last,
output: pool.next(),
commandBuffer: commandBuffer,
device: device,
pipelineCache: pipelineCache
)
try Self.compositePreemphasis(
input: pool.last,
texA: pool.next(),
texB: pool.next(),
output: pool.next(),
filter: compositePreemphasisFilter,
preemphasis: effect.compositePreemphasis,
commandBuffer: commandBuffer,
device: device,
pipelineCache: pipelineCache
)
try Self.videoNoise(
input: pool.last,
tex: pool.next(),
output: pool.next(),
filter: noiseFilter,
zoom: effect.compositeNoiseZoom,
contrast: effect.compositeNoiseContrast,
frameNumber: frameNum,
commandBuffer: commandBuffer
)
// ...
commandBuffer.commit()
commandBuffer.waitUntilCompleted()
return CIImage(mtlTexture: pool.last)
}
The important takeaway here is that the same command buffer is passing through multiple functions, collecting Metal function invocations along the way. When we’re ready for the GPU to perform the work we commit and wait, returning a new CIImage with the contents of the last-rendered-to texture.
Unlike CoreImage, which lets us stitch multiple filters together with outputImage and inputImage, working with Metal requires us to keep tabs on which textures have been drawn to when. For example, we drew to texture A in step 1, then texture A needs to be used as the input texture in step 2.
It’s preferred to triple-buffer textures, so that one function’s output texture becomes the next function’s input texture (i.e., the last-rendered-to texture becomes the next input while the “spare” texture becomes the next output.) The Pool class helps us manage this, so we don’t have to hard-code references to specific textures in the pipeline. This also lets us skip past or comment out sections of the filter and maintain the pipeline’s integrity.
class Pool<A> {
typealias Element = A
let vals: Array<Element>
var currentIndex = 0
init(vals: Array<Element>) {
self.vals = vals
}
func next() -> Element {
defer { currentIndex = (currentIndex + 1) % vals.count }
return vals[currentIndex]
}
var last: Element {
let prevIndex = currentIndex - 1
if vals.indices.contains(prevIndex) {
return vals[prevIndex]
} else {
let lastIndex = vals.endIndex - 1
return vals[lastIndex]
}
}
}
The individual filter instances (e.g., CompositePreemphasisFilter) are used to encapsulate the Metal boilerplate.
public class CompositePreemphasisFilter {
typealias Error = TextureFilterError
private let device: MTLDevice
private let pipelineCache: MetalPipelineCache
private var highpassFilter: HighpassFilter
var preemphasis: Float16 = NTSCEffect.default.compositePreemphasis
init(frequencyCutoff: Float, device: MTLDevice, pipelineCache: MetalPipelineCache) {
self.device = device
self.pipelineCache = pipelineCache
let lowpass = LowpassFilter(frequencyCutoff: frequencyCutoff, device: device)
self.highpassFilter = HighpassFilter(lowpassFilter: lowpass, device: device, pipelineCache: pipelineCache)
}
func run(input: MTLTexture, texA: MTLTexture, texB: MTLTexture, output: MTLTexture, commandBuffer: MTLCommandBuffer) throws {
let highpassed = texA
let spare = texB
try highpassFilter.run(input: input, tex: spare, output: highpassed, commandBuffer: commandBuffer)
try encodeKernelFunction(.compositePreemphasis, pipelineCache: pipelineCache, textureWidth: input.width, textureHeight: input.height, commandBuffer: commandBuffer, encode: { encoder in
encoder.setTexture(input, index: 0)
encoder.setTexture(highpassed, index: 1)
encoder.setTexture(output, index: 2)
var preemphasis = preemphasis
encoder.setBytes(&preemphasis, length: MemoryLayout<Float16>.size, index: 0)
})
}
}
And encodeKernelFunction wraps up even more.
func encodeKernelFunction(_ kernelFunction: KernelFunction, pipelineCache: MetalPipelineCache, textureWidth: Int, textureHeight: Int, commandBuffer: MTLCommandBuffer, encode: (MTLComputeCommandEncoder) -> Void) throws {
let pipelineState = try pipelineCache.pipelineState(function: kernelFunction)
guard let encoder = commandBuffer.makeComputeCommandEncoder() else {
throw TextureFilterError.cantMakeComputeEncoder
}
encoder.setComputePipelineState(pipelineState)
encode(encoder)
let executionWidth = pipelineState.threadExecutionWidth
encoder.dispatchThreads(
threadsPerGrid: MTLSize(width: textureWidth, height: textureHeight, depth: 1),
threadsPerThreadgroup: MTLSize(width: executionWidth, height: executionWidth, depth: 1)
)
encoder.endEncoding()
}
It relies on MetalPipelineCache, which is responsible for caching the MTLComputePipelineStates that represent the Metal functions we want to call.
class MetalPipelineCache {
enum Error: Swift.Error {
case cantMakeFunction(KernelFunction)
case underlying(Swift.Error)
case noPipelineStateAvailable
}
let device: MTLDevice
let library: MTLLibrary
init(device: MTLDevice, library: MTLLibrary) throws {
self.device = device
self.library = library
// Warm cache
for function in KernelFunction.allCases {
_ = try pipelineState(function: function)
}
}
var pipelineStateByFunction: [KernelFunction: MTLComputePipelineState] = [:]
func pipelineState(function: KernelFunction) throws -> MTLComputePipelineState {
if let pipelineState = pipelineStateByFunction[function] {
return pipelineState
}
guard let fn = library.makeFunction(name: function.rawValue) else {
throw Error.cantMakeFunction(function)
}
do {
let pipelineState = try device.makeComputePipelineState(function: fn)
self.pipelineStateByFunction[function] = pipelineState
return pipelineState
} catch {
throw Error.underlying(error)
}
}
}
Instantiating Textures
Unlike Core Image, when working with Metal, we’re responsible for the creation and ownership of the textures we need. To create them, we can use a MTLTextureDescriptor:
static func texture(width: Int, height: Int, pixelFormat: MTLPixelFormat, device: MTLDevice) -> MTLTexture? {
let textureDescriptor = MTLTextureDescriptor.texture2DDescriptor(
pixelFormat: pixelFormat,
width: width,
height: height,
mipmapped: false
)
textureDescriptor.usage = [.shaderRead, .shaderWrite, .renderTarget]
return device.makeTexture(descriptor: textureDescriptor)
}
Since we want to store negative floating point values in our NTSC filter, we can declare our pixel format as .rgba16Float.
So that’s pretty much it! You can see how we start off with a Metal function that we want to call, build up a compute pipeline, add the function invocations to a command buffer, and retrieve our final processed image data on the other end.
Integration
Of course, the individual frame buffers need to come from somewhere. Below, I’ll show two examples – one for live video feed data, and the second for offline processing of an existing AVAsset.
Live Video
Recording from the camera on iOS can be managed with AVCaptureSession – we just need to insert ourselves as the delegate in order to get the following callback:
func captureOutput(_ output: AVCaptureOutput, didOutput sampleBuffer: CMSampleBuffer, from connection: AVCaptureConnection) {
guard let pixelBuffer = CMSampleBufferGetImageBuffer(sampleBuffer) else {
return
}
let ciImage = CIImage(cvImageBuffer: pixelBuffer)
.oriented(forExifOrientation: Int32(CGImagePropertyOrientation.right.rawValue))
self.lastImage = ciImage
DispatchQueue.main.async {
self.mtkView.setNeedsDisplay()
}
}
This gives us a buffer that we can process the next time our MTKView is ready for a frame (which we signal by calling setNeedsDisplay above.) Since we’ve set ourselves as the MTKView.delegate, we’ll be expected to implement the draw(in:) method, which is where we actually filter our input image.
func draw(in view: MTKView) {
guard let lastImage else {
return
}
guard let drawable = view.currentDrawable else {
return
}
guard let commandBuffer = self.commandQueue.makeCommandBuffer() else {
return
}
let dSize = view.drawableSize
let destination = CIRenderDestination(
width: Int(dSize.width),
height: Int(dSize.height),
pixelFormat: view.colorPixelFormat,
commandBuffer: commandBuffer,
mtlTextureProvider: {
drawable.texture
})
// Apply NTSC filter
filter.inputImage = lastImage
guard let outputImage = filter.outputImage else {
return
}
let widthMultiple = dSize.width / outputImage.extent.size.width
let heightMultiple = dSize.height / outputImage.extent.size.height
let scaleFactor = max(widthMultiple, heightMultiple)
let scaledImage = outputImage.transformed(by: CGAffineTransform.init(scaleX: scaleFactor, y: scaleFactor))
do {
try ciContext.startTask(toRender: scaledImage, to: destination)
commandBuffer.present(drawable)
commandBuffer.commit()
} catch {
print("Error starting render task: \(error)")
}
}
The code above shows how we can ask the MTKView for its current drawable, generate a CIImage, and asynchronously render to the screen using CIRenderDestination.
Offline Processing
There are a couple of hooks into processing the frames of an existing AVAsset. The simplest is a static AVVideoComposition method that allows us to do our image processing in a closure. The system provides us with an input CIImage and we call a closure argument with our resulting output. is found in AVVideoComposition and its customVideoCompositorClass property, which gives us low-level access to the underlying CVPixelBuffer data for each of the tracks in our composition. This is the route we want to take if we’re doing multitrack video editing.
final class LayerVideoCompositor: NSObject, AVVideoCompositing {
private var renderContext = AVVideoCompositionRenderContext()
static let ciContext = CIContext(options: [.cacheIntermediates: false])
enum LayerVideoCompositingError: Error {
case sourceFrameBuffer
case ciFilterCompositing
}
func startRequest(_ request: AVAsynchronousVideoCompositionRequest) {
do {
let renderedBuffer = try renderFrame(forRequest: request)
request.finish(withComposedVideoFrame: renderedBuffer)
}
catch {
request.finish(with: error)
}
}
private func renderFrame(forRequest request: AVAsynchronousVideoCompositionRequest) throws -> CVPixelBuffer {
return try autoreleasepool {
switch request.videoCompositionInstruction {
case let myInstruction as MyVideoCompositionInstructionImplementation:
return try renderFrame(request: request, instruction: myInstruction)
default:
throw LayerVideoCompositingError.invalidRequest
}
}
}
func renderStandardFrame(request: AVAsynchronousVideoCompositionRequest, instruction: StandardVideoCompositionInstruction) throws -> CVPixelBuffer {
guard let videoFrameBuffer: CVPixelBuffer = request.sourceFrame(byTrackID: instruction.videoTrackID) else {
throw LayerVideoCompositingError.sourceFrameBuffer
}
let inputImage = CIImage(cvPixelBuffer: videoFrameBuffer)
let outputImage = applyMetalFilter(to: inputImage)
guard let renderedBuffer = renderContext.newPixelBuffer() else {
throw LayerVideoCompositingError.ciFilterCompositing
}
let renderDestination = CIRenderDestination(pixelBuffer: renderedBuffer)
try Self.ciContext.startTask(toRender: outputImage, to: renderDestination)
return renderedBuffer
}
}
The conversion of videoFrameBuffer to a CIImage can be dropped in favor of rendering the pixel buffer directly to a texture if Core Image isn’t part of your processing pipeline.
And that’s it! We’ve discussed the role of command buffers and how to stitch them through multiple processing kernels, some helper code for setting up pipelines, how to instantiate and cycle textures, and how to tie our Metal processing into live and offline video processing. Happy shading!
14 Jul 2024
After 11 years, I’m finally back at the Recurse Center. In preparing for my batch, I planned to work on something completely unrelated to video. I’d wanted to branch out into front- and back-end web development, learn some dev ops, and get into topics like distributed systems and CRDTs. But on the first day, I met the amazing Valadaptive, whose project NTSC-RS is a toolkit for building vintage image filters. I became fixated on the possibilities for iOS and started digging through the repo, learning about the project’s predecessors and the foundations that give old video its distinctive look.
For context, my work at 1 Second Everyday revolves entirely around video, and it’s something that I’ve taken a deep interest in. Coincidentally, I’ve tried to build a naive camcorder filter multiple times in the past, even reaching out to Apple engineers for help thinking about the problem. I’ve scoured the web and Shadertoy but I’ve never been happy with the results I’ve been able to produce. I didn’t have a sense of how the adjustments that I’d built might converge on a realistic effect, or what other layers I’d need to build in order to make it happen. NTSC-RS felt like a map to buried treasure, but first I’d need to orient myself. The obvious question I faced was, “what even is NTSC video?”
NTSC Video

Short for National Television Standards Committee, NTSC was the original standard for analog TV in the US, and evolved in 1953 to support color TV. TVs and VHS players and cameras in the Americas and elsewhere used the NTSC color system, encoded to YIQ (Luminance, In-Phase, Quadrature,) until the rise of digital technologies in the 1990s. Backward compatibility with black-and-white sets was maintained by transmitting the black-and-white luminance data on a separate subcarrier from the chroma (color) channels, much in the same way stereo FM radio works.
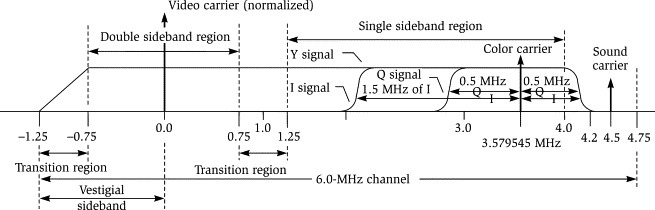
Ultimately, this YIQ model would be the key to the whole project. The basic architecture would look like this:
- Decode an input frame
- Convert the RGB data to YIQ
- Perform some operations on the YIQ data
- Convert back to RGB
- Render
Step 3 is where the real work of the filter would happen, by applying blurs, highpass and lowpass filters, noise, etc. to one or more of the three YIQ channels. This would be how to achieve effects like color bleed, luminance noise, or bleeding from luma into chroma (and vice versa.)
Porting to Swift and Core Image
Getting started, my game plan was to port the existing Rust code to Swift and Core Image, moving off the CPU and onto the GPU in order to have something performant enough for live video recording or filtering live video playback. Along the way I could run the Rust code, writing tests on both platforms and stepping through them in the debugger to make sure I was on the right track.
All of the image processing I’d done up to this point used Apple’s Core Image framework, which has a multitude of builtin filters that can be composed together in a performant way. When you need custom filters you can write a CIColorKernel in Metal using the Metal Shader Language (a dialect of C++.) I assumed that this is the approach I’d use to write my NTSC code. It was not to be.
The big thing I’d overlooked is that in the RGB color model, channel values are bounded by 0. You can’t have an R, G, or B value that’s less than pure black. But YIQ isn’t bounded in this way, and negative values are everywhere. My plan had been to store YIQ images as regular CIImages, but the zero lower bound made this impossible. Enter Metal.
Metal is Apple’s graphics programming framework, designed as a modern low-level replacement for OpenGL on Apple’s platforms. As I mentioned above, Core Image kernels are written in Metal already. I just needed to make sure that I’d be able to store negative values in my “pixel data,” then I could simply store Y, I, and Q values where R, G, and B ones would ordinarily be.
When writing image processing code in Metal, the two main components are textures and shaders. Textures can be thought of as multidimensional arrays of vectors, and for our purposes are the backing stores for our images’ pixel data. Shaders are programs written to be executed on the GPU, and the ones we care about (fragment shaders) are designed to be run once per pixel. In this way, you could say that CIColorKernels are themselves a special kind of fragment shader.
Unlike regular Core Image code, which is essentially functional (input image in, output image out,) Metal shaders will take one or more input textures as arguments and write to an output texture. Here’s some sample code to give you an idea
let encoder: MTLComputeCommandEncoder = ...
encoder.setTexture(input, index: 0)
encoder.setTexture(output, index: 1)
var min: Float16 = min
encoder.setBytes(&min, length: MemoryLayout<Float16>.size, index: 0)
var max: Float16 = max
encoder.setBytes(&max, length: MemoryLayout<Float16>.size, index: 1)
You can see that we’re setting textures and values on the encoder, assigning indices to each one. This is how we’ll be able to access them on the Metal side.
kernel void mix
(
texture2d<half, access::read> input [[texture(0)]],
texture2d<half, access::write> out [[texture(1)]],
constant half &min [[buffer(0)]],
constant half &max [[buffer(1)]],
uint2 gid [[thread_position_in_grid]]
) {
half4 px = input.read(gid);
half4 mixed = mix(min, max, px);
out.write(mixed, gid);
}
The line kernel void mix declares a Metal kernel (shader) whose return type is void and name is mix. We have access to the two textures and two values that we set in the Swift code, taking care to make sure the indices match up (note that 16-bit floating point numbers are called halfs in Metal but they’re identical to Swift’s Float16 type. Ditto float and Float.) The last three lines read a pixel from the input texture using gid (the current XY coordinate,) call the mix function in Metal (different from our kernel with the same name) using the pixel data and our min and max arguments, and write the new pixel back out to out. Finally, we can use an MTKView to get this texture data onscreen. Note that input and out have access values of read and write, respectively. This protects you from accidentally writing to your input texture or vice versa. Similarly, the texture and buffer indices are checked for uniqueness at compile time. It’s no Swift type system, but it’s something.
Boilerplate
“Sure,” you might ask, “but how do I actually get the GPU to run this code?” Generally, there’s some boilerplate that we need to do every frame:
- Get a command buffer
- For each function we want to call, encode it and its textures and data to the buffer
- Commit the buffer (and optionally wait for it to finish executing)
1. Getting Command Buffers
You get these from a MTLCommandQueue. You only ever need one queue so you’ll want to create it and hold onto it, since they’re expensive to create. You do this using your MTLDevice, which itself is the root-level object for interacting with Metal. Generally, you’ll get access to a device instance by calling MTLCreateSystemDefaultDevice.
class MyClass {
private let device: MTLDevice
private let commandQueue: MTLCommandQueue
init?() {
guard let device = MTLCreateSystemDefaultDevice() else {
return nil
}
self.device = device
guard let commandQueue = device.makeCommandQueue() else {
return nil
}
self.commandQueue = commandQueue
}
}
extension MyClass: MTKViewDelegate {
func draw(in view: MTKView) {
guard let commandBuffer = commandQueue.makeCommandBuffer() else {
return
}
...
}
}
As shown above, you’ll usually want to generate a command buffer in response to some event, say an MTKViewDelegate callback or AVVideoCompositing.startRequest(_:). You can think of command buffers as “buffers full of commands” that you’re going to send to the GPU.
2. Encoding Function Calls
The basic pattern is going to look like this
// Get a command encoder from the buffer to encode a command
let encoder: MTLComputeCommandEncoder = commandBuffer.makeComputeCommandEncoder()!
// Set up the pipeline state (i.e., encode a reference to your function)
let library: MTLLibrary = device.makeDefaultLibrary()!
let fn: MTLFunction = library.makeFunction(name: "mix")!
let pipelineState: MTLComputePipelineState = device.makeComputePipelineState(function: fn)!
encoder.setComputePipelineState(pipelineState)
// Encode references to your textures and parameters
encoder.setTexture(...)
encoder.setBytes(...)
// Dispatch threads (describe how you want the GPU to process the request)
encoder.dispatchThreads(...)
encoder.endEncoding()
A couple of points to keep in mind:
- You want to instantiate your library once and hold a reference to it
- Your pipeline states are expensive to create and should be cached and reused (you can use a dictionary keyed by function name)
- We covered setting textures and bytes above.
MTLBuffers behave the same if you need to use those.
- If you don’t call
dispatchThreads(_:threadsPerThreadgroup:) your function won’t actually be invoked.
- You need to remember to call
endEncoding, otherwise you’ll get a crash when you start trying to encode your next command.
For dispatchThreads the approach I’ve been taking is:
threadsPerGrid: MTLSize(width: textureWidth, height: textureHeight, depth: 1)threadsPerThreadgroup: MTLSize(width: 8, height: 8, depth: 1). There seems to be some debate over the appropriate value here and it might be worth experimenting with other multiples of 8 to see the performance impacts on your application.
This method details how you want Metal to apportion resources to run your function. The first argument represents the total number of elements (pixels) that need to be processed, and the second is how big you want your threadgroups to be (how much parallelism you want.) Here’s a link to the developer documentation if you’re interested in learning more.
3. Committing
let buffer: MTLCommandBuffer = ...
...
buffer.commit()
buffer.waitUntilCompleted()
In our case, we want to wait until the buffer has been processed so that we can use our final texture to render a CIImage or whatever but that’s pretty much it!
Recap
Now that we know how to set up a Metal pipeline, encode functions and data, and get our code to run on the GPU, we can build arbitrary image processing tools outside of what’s achievable with Core Image alone. To recap:
- Some objects are long-lived:
MTLDevice, MTLCommandQueue, and MTLLibrary, as well as a pool of MTLTextures (covered in the next post)
- Every time we render a frame, we need to encode all of the functions that we want to call, along with references to textures and any data that the functions need in order to run. We do this with a fresh command encoder for each function invocation. The functions will run in the order they’ve been added to the command buffer.
- Part of encoding a function invocation is making sure you’ve set up the correct pipeline state, dispatched threads, and ended encoding.
In the next post I’ll detail how to integrate a Metal pipeline with video streams, show you some glue code to make everything a little less verbose, and take a step back to look at the trip a command buffer takes through your image pipeline.
25 May 2024

In a miracle of luck and timing, I’ve been afforded the opportunity to come back to the Recurse Center to focus on personal programming projects for the next six weeks (already down to five.) My plan is to blog here to keep myself accountable and to have a public document of my time at RC.
I first came to RC (formerly Hacker School) back in October of 2013. I was living in Japan, working as a reporter, when I happened to come across a tweet. It read something like “Love programming? Apply to Hacker School!” Clicking that link changed my life in innumerable ways, but most importantly, it gave me the opportunity to do what I love for a living – to be able to support myself while pursuing my own interests and scratching the analytical part of my brain that always felt unsatisfied at other jobs.
The thing that makes RC special is that it’s engineered to maximize the likelihood of making you a dramatically better programmer. Every core batch event is designed to train your focus on something just outside your current abilities; something that you might know how to start, but not know how to see through to completion. Tackling these kinds of projects are what RC is all about, and the work that people have produced here is mind-blowing. Just off the top of my head, a handful of presentations this week covered:
Even though this is my first time in the “new” Downtown Brooklyn space, I’m struck by how similar the energy feels. The library is bigger, the hardware lab is better, and there’s a 3D printer and scanner. At the same time, it seems like the batches have become more self-sustaining, with a new rice cooker for cooking group meals, a new espresso machine, and a pantry stocked with tons of snacks that people donate and share. The walls are covered with guides, handmade art projects, and programmable gizmos of all kinds – the physical dotfiles that have built up over the scores of batches spent here.
I always tell people that my first batch in 2013 was the best three months of my life, and getting the chance to experience it again is very meaningful. I’m incredibly grateful to be be back, and so thankful to Nick, Sonali, Dave, and all the other faculty and batchmatches past and present for making this place what it is.
29 Mar 2020
Core Data has always been a weak area for me. I’ve never worked with it professionally, and even though I’ve worked on a big project with Realm, I felt like I could use a refresher on it, too. So instead of following the plan and reading one book a month, I read three over the course of February and March:
- Core Data by Florian Kugler and Daniel Eggert
- Core Data by Tutorials by Aaron Douglas, Matthew Morey, and Pietro Rea
- Realm: Building Modern Swift Apps with Realm Database by Marin Todorov
How were the books?
I learned a lot from all three, but I wish I’d read the Ray Wenderlich one on Core Data before reading Objc.io’s since it gives a much better introduction for people that have never touched the framework. But even though the Objc.io one’s introductory chapters are rougher it still supplies a lot of handy convenience functions and clearly lays out some best practices. I’m a fan of Florian’s coding style from the other books and videos and found plenty to like in it.
Unlike the Wenderlich book, the Objc.io one is not really project-based. For that reason, it’s more difficult to follow along with the sample code, and sometimes the explanations are worded in a way that makes me wonder whether it’s a mistake or if I’m misunderstanding from earlier. Sidenote: I’d love to see the material get the same video series treatment as their newer books on app architecture, optimizing collections, and Swift UI in a future revision.
The Realm book is also from the team at Ray Wenderlich and feels very comparable to their Core Data one in terms of scope, building up the sample projects, etc. As someone who’s done a decent amount of work with Realm I still learned some useful things, and wouldn’t hesitate to recommend it to someone wanting to jump into Realm for the first time.
Should I use Core Data or Realm for my project?
This is obviously going to depend a lot on your use case, but I’d sum up how I think about the two like this:
- Core Data is like a framework for building object graph management solutions. You can control every aspect of how data moves to and from disk, what your memory footprint looks like at any given moment, and how your multithreaded code behaves.
- Realm has batteries included. There’s generally one right way to do something, and you don’t need to understand much to use it correctly in simple cases.
I would reach for Core Data if I was trying to minimize my dependency on third-party libraries, or if I had a need to work with large graphs of managed objects and wanted to optimize reads and writes very tightly. To give you a sense of what I mean, executing a fetch request always involves a round-trip to disk, so you want to limit how frequently you’re performing them. The data that’s included in those fetch results typically contain faults – references to other managed objects that haven’t been populated yet. You determine when you want to pay for the faults to be filled. Changes that you make in the “scratchpad” (context) have to be explicitly saved to disk. You can use “subentities” if you want multiple types of managed objects to be stored together in the same database table for performance, but these subentities don’t behave like subclasses. The list goes on.
I would go for Realm if I was just trying to get something up and running. Specifying a schema is as simple as inheriting from Realm.Object and async code is easy to understand. For example, any time you mutate a managed Realm object it needs to be in a write transaction, and other parts of your code that are listening for these changes are notified autmatically. In general, it seems like it’s less powerful and gives you less control, but there are fewer opportunities to shoot yourself in the foot.
Random Learnings
Core Data
- You can’t pass Core Data contexts or objects across threads. For access to an object on a separate thread you’ll want its
NSManagedObject.objectID, which is threadsafe.
- Core Data’s persistent store coordinator will keep all contexts backed by the same persistent container up to date. This means that you can save changes to your object on
context1 and context2 will see them if it looks for them. You can keep the two in sync pretty easily by subscribing to the relevant notifications.
- A lot of the complaints I’ve heard from people who work with Core Data revolve around reasoning about child contexts. The way they’re presented in the Wenderlich book seems to be entirely as in-memory scratchpads whose changes you can either commit or throw away. Calling
save() on a child context only saves those changes to the parent context, not to the store.
- The Objc.io book comes out pretty strongly against nested contexts, with the exception of the single parent-child case.
Realm
- Realm can be made very performant when you need to do a ton of writes, but it requires some screwing around to get a run loop installed on a background thread.
- It allows reads and writes from any thread, publishing notifications on the thread they were created from. The realm and its objects can’t be passed across threads.
- Calling
Realm(configuration:) to initialize a new realm is usually a lightweight operation because the framework will return an existing instance for the current thread if one’s available. In general, you shouldn’t hold onto realm instances and should hold onto the configuration and initialize on the fly instead. (There’s an exception when you’re writing to a single dedicated thread.)
- By default, adding an object to a realm where another object of the same type shares its primary key will error instead of applying the changes.
- It’s very simple to set up Realm Cloud, at least with their PaaS (not sure about self hosting.)
Differences and similarities
- Unlike Core Data, Realm doesn’t allow for cascading deletes out of the box, but the Wenderlich book shows you how to build a simple implementation.
- Migrations in Core Data and Realm seem more or less similar. The same kinds of automatic migrations can be performed for you, and you perform more complex migrations in a similar way. Core Data provides a graphical editor for its data models, giving you a way to map old to new by specifying stuff in a GUI (“custom mapping model”) as a middle ground between a fully automatic migration and a fully custom one.
Conclusion?
The abstractions in Core Data are a lot cooler than I thought they were, and it seems like a lot of people’s complaints about it are probably more related to complex configurations than poor design decisions by the framework’s authors. That said, I like that Realm makes easy things easy, and for a lot of projects, the sacrifice in performance and predictability will be justified by the reduced engineering effort to keep things working.
31 Jan 2020

Lately I’ve been wanting to do more learning outside work hours, so when my coworkers shared their personal goals for 2020 in Slack, I thought, “This is the year I read a technical book a month.” Since I work with AVFoundation every day at 1 Second Everyday, I figured what better way to start than with a book-length treatment of my favorite (?) framework, Bob McCune’s Learning AV Foundation: A Hands-on Guide to Mastering the AV Foundation Framework. At 432 pages it covers a lot of ground, with walkthroughs on media playback and capture, working with assets and metadata, and composition and editing. It starts from the very basics (how digital media is represented on disk) and works up to more complex topics – from how to work with rational time to how to control focus and exposure on iPhone cameras, eventually building up to a multitrack editing app by the end of the book.
I love technical books like David Beazley’s Python Essential Reference – they explain complex ideas in terse, well-formulated language, give a clear structure and progression, and steer clear of the jokey voice that shows up everywhere in tech books for beginners. I wouldn’t put Learning AV Foundation in quite the same tier – it’s a project-based book and not really a reference – but it was a good read, communicated the main ideas clearly, and provided enough scaffolding that the project work could be really focused on what he’s trying to teach in a given chapter. I won’t spoil what’s in the book, but here are a handful of takeaways from someone who’s spent the last 8 months or so working with AV Foundation:
- I had no idea about the atom/box structure of MP4 and QuickTime files. I wish that Apple’s Atom Inspector app was updated to run on recent OSes – please consider filing a Radar referencing this report if you’d like the same. Also, any recommendations for other inspection tools for MP4 and MOV?
- The richness of metadata that MP4 and QuickTime can support is really cool. In particular, the idea that you can add dictionaries containing your own structured data to a video file.
- How simple it is to set up AirPlay
- How
AVCaptureSession works and how you can wire different inputs and outputs up to it
So what’s not to like about it?
- All Objective-C
- Some stuff is outdated (published in 2015) and the source code contains a couple of frustrating errors
- Reading code in the iBooks ePUB version is really bad, and pretty typical. I’d recommend a physical copy or PDF if possible.
- I would love to have had a treatment of some higher-level ideas, like dealing with multiple timescales and performance considerations for custom video compositors.
I’d definitely give it a thumbs up overall and would recommend it to people who want a broad overview of the framework. It goes pretty deep in parts (AVAssetWriter, AVVideoCompositionCoreAnimationTool, AVCaptureVideoDataOutput) and always leaves the reader with enough clues to continue digging on their own.